Disclaimer: This is a research prototype and not an officially supported ByteDance product.
Special Thanks: We give special thanks to Kelly Zhang, Ziyan Zhang, Yang Zhao, and Jiaming Han for their support and discussion.
Recent video generation models have shown promising results in producing high-quality video clips lasting several seconds. However, these models face challenges in generating long sequences that convey clear and informative events, limiting their ability to support coherent narrations. In this paper, we present a large-scale cooking video dataset designed to advance long-form narrative generation in the cooking domain. We validate the quality of our proposed dataset in terms of visual fidelity and textual caption accuracy using state-of-the-art Vision-Language Models (VLMs) and video generation models, respectively. We further introduce a Long Narrative Video Director to enhance both visual and semantic coherence in generated videos and emphasize the role of aligning visual embeddings to achieve improved overall video quality. Our method demonstrates substantial improvements in generating visually detailed and semantically aligned keyframes, supported by finetuning techniques that integrate text and image embeddings within the video generation process.
Demos below showcase our long narrative video generation capabilities through three main sections:
Showcasing our core method that uses interleaved visual embeddings to generate coherent cooking videos with strong temporal consistency.
Demonstrating an alternative approach using FLUX.1-Schnell for high-quality frame generation guided by textual descriptions.
Exploring broader applications beyond cooking, including a Tesla car advertisement, a Batman vs. Ironman movie trailer, and a Netflix-style animal documentary trailer.
Our Long Narrative Video Director uses interleaved visual embeddings as conditions for Video Generation. This approach emphasizes visual alignment throughout the generation process, resulting in more realistic and consistent cooking demonstrations. The generated content maintains better temporal coherence and visual consistency across steps.
This approach leverages generated captions to create keyframes using the SOTA Text-to-Image model (FLUX.1-Schnell). While this method produces more aesthetically pleasing individual frames, it may show less visual consistency between steps. The result emphasizes artistic quality while maintaining strong alignment with textual descriptions.
In this section, we also provide two more demos to show the potential of our pipeline to broader scenarios:
Tesla Car Product Video and Animal Documentary Trailer.
CookGen contains long narrative videos annotated with actions and captions. Each source video is cut into clips and matched with labeled "actions". We use refined pseudo labels from ASR for Howto100M videos and manual annotations for Youcook2 videos. High-quality captions are generated using state-of-the-art VLMs (GPT-4 and a finetuned video captioner) for all video clips.

Dataset annotation and curation pipeline: We collect cooking videos from Howto100M and Youcook2, segment them into clips, and annotate them with actions and captions using a combination of ASR, manual annotation, and SoTA VLMs.
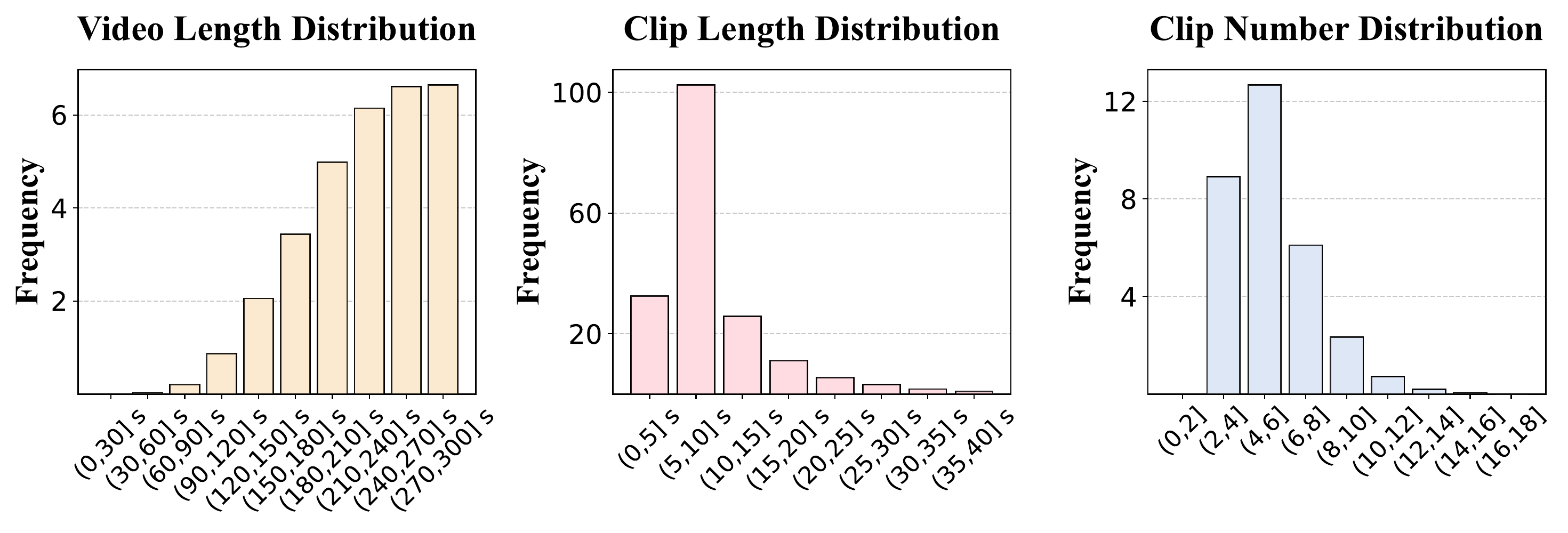
Video Data Statistics: Our dataset features videos ranging from 30-150 seconds in length, with individual clips spanning 5-30 seconds. Each video is divided into 4-12 clips, providing a balanced distribution that ensures comprehensive coverage of cooking procedures.
Text Annotation Statistics: The dataset includes detailed text annotations with actions containing 10-25 words and comprehensive captions spanning 40-70 words. When tokenized, actions typically contain 20-60 tokens, while captions can extend up to 120 tokens, providing rich descriptive content.
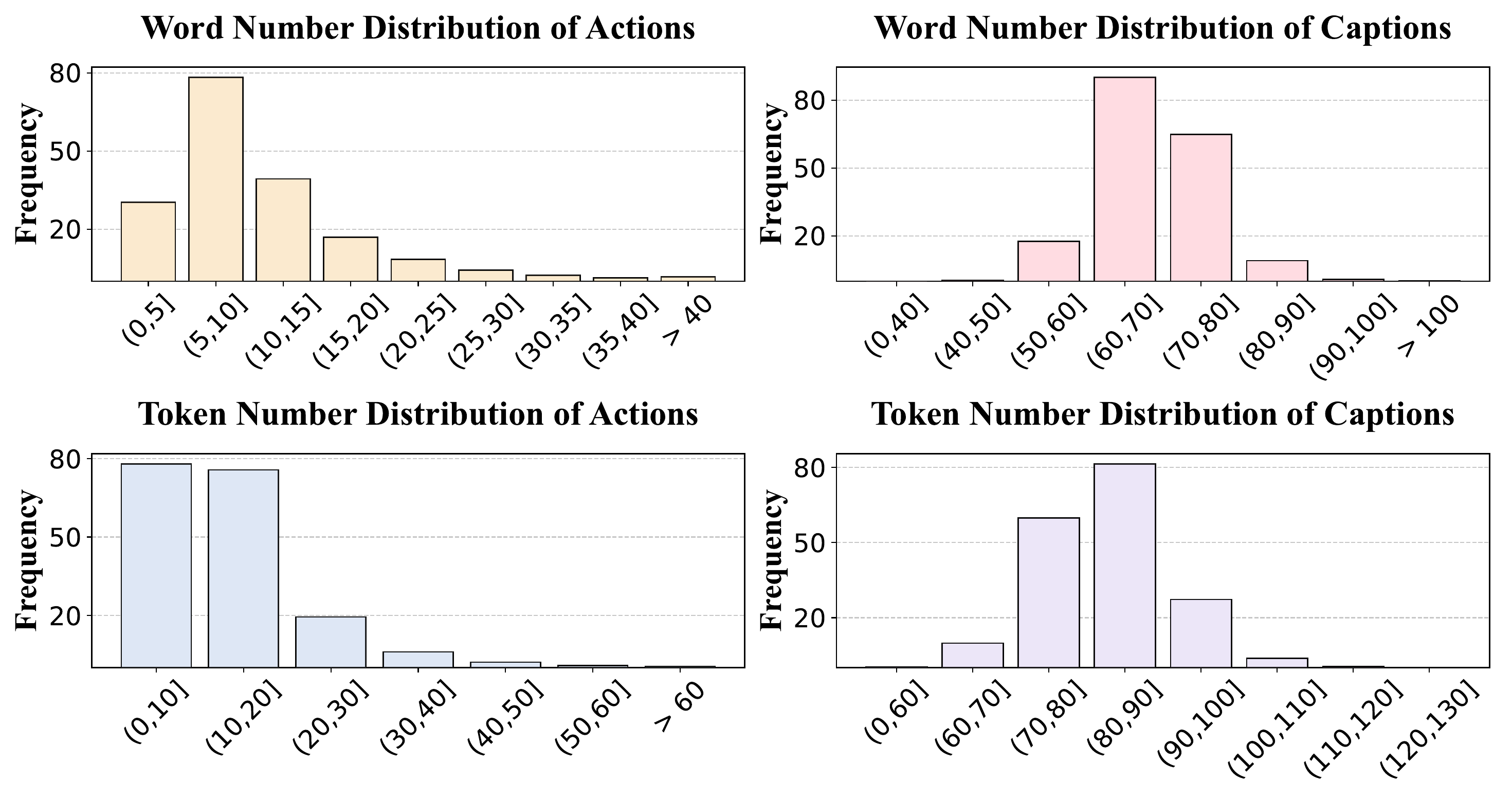
These statistics demonstrate the high quality and suitability of our dataset for long narrative video generation. The balanced distribution of video lengths and clip counts ensures proper narrative structure, while the detailed text annotations provide rich contextual information for each segment. This comprehensive annotation approach enables well-aligned and contextually rich representations of the video content.
Given the text input, the task of long narrative video generation aims at generating a coherent long video that aligns with the progression of the text input sequentially. To achieve this, we propose VideoAuteur, a pipeline that involves two main components: a long narrative video director and visual-conditioned video generation.

We use an interleaved auto-regressive model to generate sequential outputs including captions, actions, and visual states. The model employs an interleaved generation approach, where each step's output informs subsequent generations. Key architectural innovations include optimized visual latent space representation, specialized regression loss functions for visual embedding accuracy, and refined regression task formulation for enhanced temporal coherence.
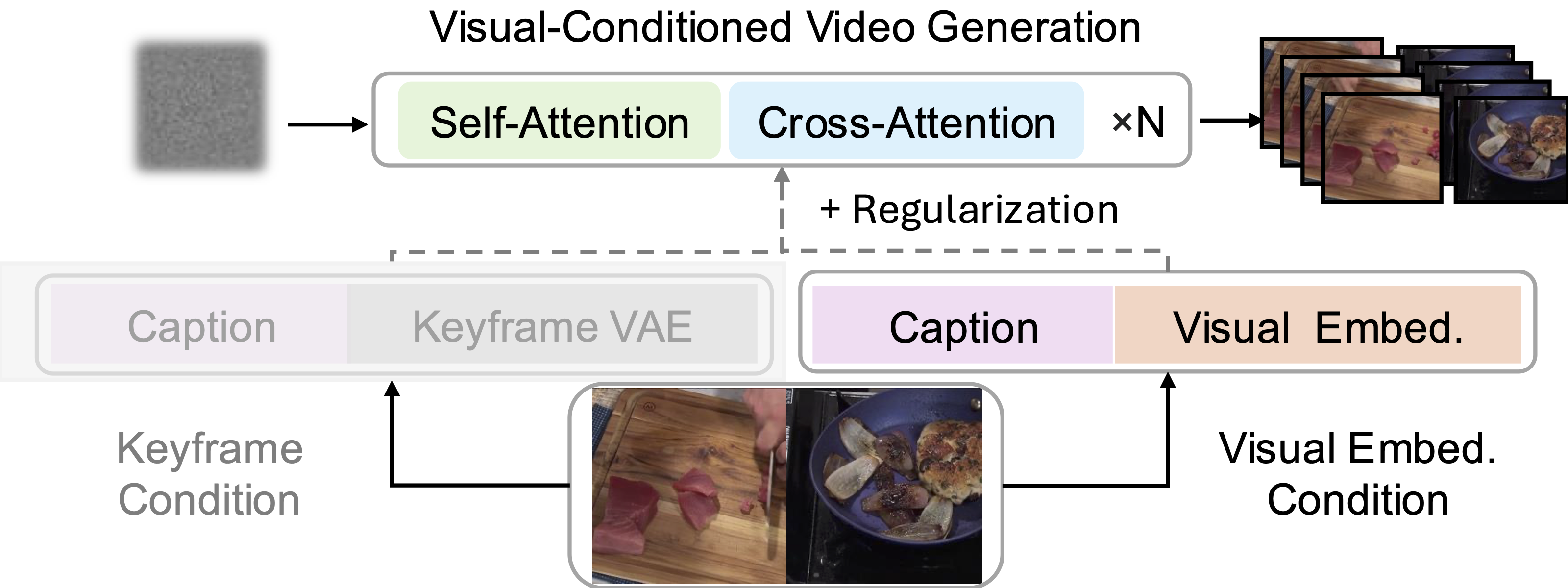
The Visual-Conditioned Video Generation framework integrates action sequences (aₜ), captions (cₜ), and visual states (zₜ) from the narrative director to synthesize coherent long-form videos. The architecture advances beyond traditional Image-to-Video approaches by implementing continuous visual latent conditioning throughout the sequence generation process. The model incorporates robust error handling mechanisms to address potential regression artifacts in visual embeddings, ensuring stable and high-quality video output despite input variations.
@article{xiao2024videoauteur,
title={VideoAuteur: Towards Long Narrative Video Generation},
author={Xiao, Junfei and Cheng, Feng and Qi, Lu and Gui, Liangke and Cen, Jiepeng and Ma, Zhibei and Yuille, Alan and Jiang, Lu},
journal={arXiv preprint arXiv:2501.06173},
year={2024}
}